
생성형 AI를 어떻게 비즈니스에 접목할 것인가? Vertex AI Embedding API에 길이 있다!
요즘 초거대 언어 모델(이하 LLM) 기반 생성형 AI(Generative AI)를 실제 비즈니스 시스템이나 디지털 제품(Digital Product) 및 서비스에 접목하는 과제를 준비 또는 실행 중인 조직이 많습니다. IT, AI, 데이터 등 전문가들이 주도적으로 과제 수행을 준비하는 경우도 있겠지만 아마 경영진에서 과제가 내려와 프로젝트를 준비 중인 곳이 더 많을 텐데요. 오픈AI의 Chat GPT와 구글 Bard가 등장하면서 남녀노소 할 것 없이 화제가 되면서 생긴 현상이 아닐까 싶은데요. 이번 포스팅에서는 생성형 AI 기술을 활용해 사내 업무나 대외 서비스에 대한 사용자 경험(UX) 개선을 숙제로 받은 분들이 반길만한 소식을 좀 전해볼까 합니다.
환상 듀오: Vertex AI Embedding API & Matching Engine
최근 구글 클라우드는 Vertex AI Embedding API를 공개했습니다. 이 기능은 다음과 같은 질문 중 하나라도 ‘YES’라고 답하는 분들에게 큰 도움이 됩니다.
✅ LLM이나 인공지능 챗봇을 기존 IT 시스템, 데이터베이스 및 비즈니스 데이터와 어떻게 통합할 것인가?
✅ 수천 개의 제품/기능이 있다면? 어떻게 LLM이 모든 제품/기능을 정확하게 기억하게 할 수 있을까?
✅ AI 채팅 봇의 환각 문제를 어떻게 처리해야 안정적인 서비스와 신뢰할 수 있는 서비스를 구축할 수 있을까?
이런 고민은 Vertex AI Embedding API와 Matching Engine 조합을 통해 생각보다 쉽게 풀어낼 수 있습니다.
Vertex AI Embedding API와 Matching Engine을 이용하면 LLM이나 인공지능 챗봇을 기존 IT 시스템, 데이터베이스 및 비즈니스 데이터와 쉽게 통합할 수 있습니다. Vertex AI Embedding API는 여러 유형의 데이터 세트를 벡터로 변환하는 데 사용되며, Matching Engine은 데이터 세트와 모델을 매칭하는 데 사용됩니다.
예를 들어 LLM이나 인공지능 챗봇을 고객 서비스 애플리케이션에 통합하려는 경우 Vertex AI Embedding API를 사용하여 각종 데이터 세트를 벡터로 변환하고, Matching Engine을 사용하여 데이터 세트와 모델을 매칭할 수 있습니다. 이를 통해 LLM이나 인공지능 챗봇이 고객의 질문을 이해하고, 더 나은 답변을 제공할 수 있습니다.
또한, Vertex AI Embedding API와 Matching Engine을 이용하면 LLM이나 인공지능 챗봇의 환각 문제를 처리할 수 있습니다. LLM이나 인공지능 챗봇은 방대한 데이터 세트로 훈련합니다. 이 경우 데이터 세트에 잘못된 정보가 포함되어 있을 수 있습니다. Vertex AI Embedding API와 Matching Engine을 이용하면 잘못된 정보를 식별하고 제거할 수 있습니다. 이를 통해 LLM이나 인공지능 챗봇에 정확한 정보를 제공할 수 있어, 신뢰도를 높이는 데 기여합니다.
그렇다면 두 조합이 문제 해결에 도움이 된다는 것은 구체적으로 무엇을 뜻할까요? 다음 문장에 답이 담겨 있습니다.

위 문장에 들어 있는 ‘임베딩(Embedding)’과 벡터 검색(Vector Search) 그리고 ‘그라운딩(grounding)’은 무슨 의미인지 먼저 살펴보겠습니다.
기술적으로 볼 때 Vertex AI Embedding API와 Matching Engine을 이용하면 임베딩과 벡터 검색을 통해 그라운딩을 할 수 있다고 표현할 수 있습니다. 이는 LLM과 현실 세계의 정보 또는 기업이 보유한 비즈니스 데이터와의 연결을 의미하는데요. 이해하기 쉽게 설명해 보겠습니다. 기존 IT 시스템에서 대부분의 데이터는 구조화된 데이터 또는 표 형식의 데이터로 구성됩니다. 반면에 AI 기반 서비스는 데이터를 임베딩이라고 하는 간단한 데이터 구조로 정렬합니다.
AI가 임베딩을 사용하여 데이터를 정리하는 방법을 살펴보겠습니다. 특정 컨텐츠에 대한 학습이 완료되면 AI는 임베딩이라는 공간을 생성합니다. 이 공간은 본질적으로 컨텐츠의 의미를 나타내는 지도입니다.
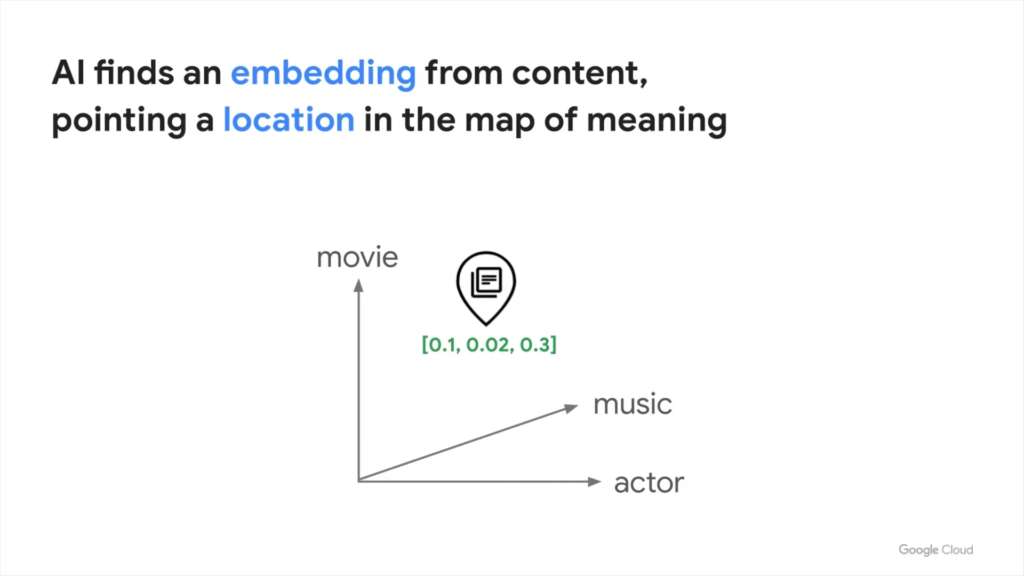
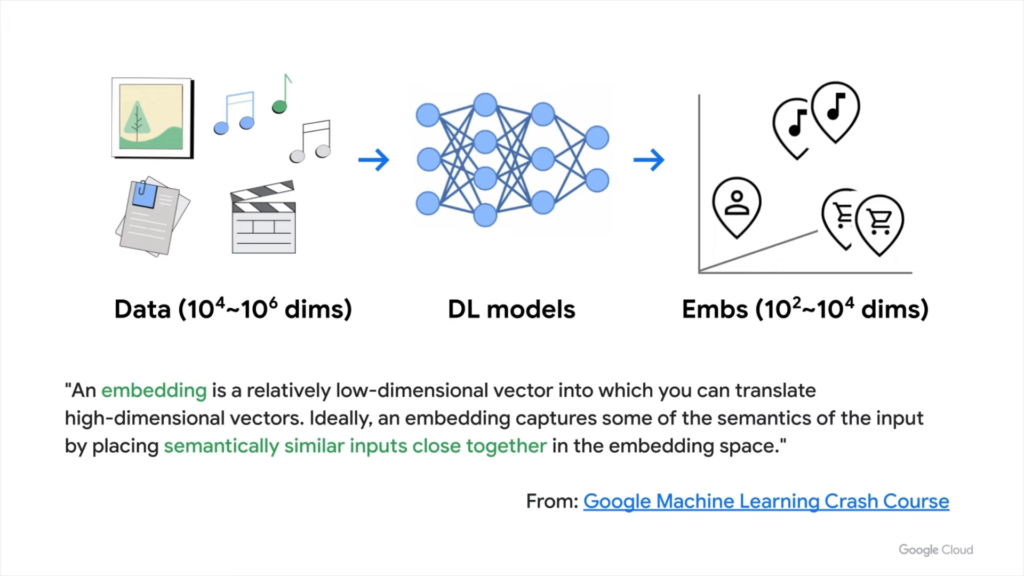
AI는 지도에서 각 컨텐츠의 위치를 식별할 수 있습니다. 이것이 바로 임베딩입니다. 위 그림은 임베딩 과정을 단순화하여 표현한 것으로, 실제로 임베딩 공간에는 수백 또는 수천 개의 차원이 있을 수 있습니다. 거의 무한대에 가까운 숫자를 나타낼 수 있는 수백 또는 수천 개의 차원을 가질 수 있습니다. 정리하자면 임베딩이란 이미지 및 텍스트와 같은 고차원 원시 데이터를 매핑하는 프로세스를 말합니다.
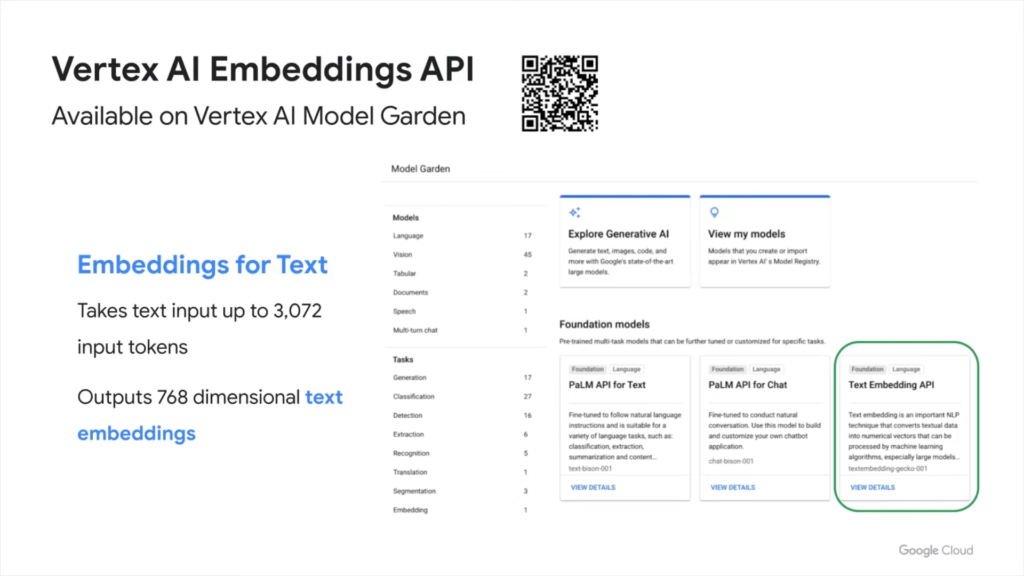
2023년 5월 10일, 구글 클라우드는 Vertex AI AI Embedding API를 발표했습니다. 이 API는 텍스트에서 임베딩을 추출하도록 설계되었는데, 이를 이용하면 임베딩과 시맨틱 검색을 결합하여 다양한 텍스트 처리 작업에 적용할 수 있습니다. 이 과정에서 적용된 것이 벡터 검색 기술입니다. 사용자의 쿼리 의도와 유사한 의미를 가진 텍스트는 벡터 검색 기술을 통해 빠르게 찾을 수 있습니다.
Vertex AI Embedding API와 Matching Engine 조합은 임베딩과 벡터 검색을 통해 그라운딩 과정을 수행하여 AI 모델이 더 나은 예측을 하고 입력에 더 정확하게 반응하도록 합니다. 그라운딩이란 모델의 이해를 실제 세계와 연결하는 프로세스를 의미합니다. 실체 및 이벤트와 연결하는 데이터를 모델에 제공하여 모델이 실제 세계를 더 잘 이해하고 상호작용할 수 있게 하는 과정이라 이해하면 됩니다.
Vertex AI Embedding API와 Matching Engine 조합을 통해 비즈니스 목적에 부합하는 데이터 세트를 효과적으로 활용할 수 있게 되면 그라운딩이 훨씬 매끄럽게 이루어져 모델이 현실 세계의 개념이나 사물을 더 잘 이해하고, 질문에 더욱 정확한 답변을 제공할 수 있습니다.
이번에는 『 생성형 AI를 비즈니스에 접목시키는 방법, Vertex AI Embedding API 』 내용을 준비해 보았습니다.
게시글을 읽고 Vertex AI Embedding API와 Matching Engine 조합을 실제 경험해보고 싶다는 생각이 든다면, Stack Overflow 시만텍 검색 데모를 검색해 보세요.
그 뒤 메가존소프트에 연락을 주시면, 생성형 AI 프로젝트를 어떻게 현실적으로 성공적으로 끌어갈 것인지에 대한 방안을 자세히 안내해 드리겠습니다. 👉 메가존소프트 문의 바로가기



